New Type-Based
Optimizations in the
SpiderMonkey VM
sotu.js 2014
Alon Zakai/@kripken

JavaScript VM Opts
Many kinds constantly being worked on: Object layout (hidden classes, etc.), garbage collection (generational GC, etc.), etc. etc.
Here I'll focus only on type-based optimizations
Type-based opts
Many benchmarks (most of kraken, parts of octane, etc.) test pure computation
Optimizations include type profiling, type inference, type specialization
Prominent in modern JS VMs (optimizing JITs like crankshaft, ionmonkey, etc.)
I'll discuss three areas of optimization, all of which only make sense given type information:
- float32
- asm.js
- backtracking register allocator
1. float32
JavaScript numbers are 64-bit doubles, but VMs has 32-bit ints as well!
Possible due to a mathematical fact about integer and double math:
xint +int yint
==
int( double(xint) +double double(yint) )
Say we are adding two values known to be 32-bit ints:
xint + yint == xint +int yint ,
assuming no overflow happened
Thankfully overflow checks are cheap, but can do even better:
(xint + yint) | 0 == xint +int yint
We can do the same for 32-bit floats!
xf32 +f32 yf32
==
f32( f64(xf32) +f64 f64(yf32) )
Also -,*,/,sqrt, etc. (but not everything, e.g. not sin)
Only true because of the exact definition of IEEE754 doubles and floats (# of bits in exponent, definition of rounding, etc.)
Where are float32 values?
Typed arrays, e.g. stuff like this is common in WebGL code
var f32 = new Float32Array(1000);
for (var i = 0; i < 1000; ++i) {
f32[i] = f32[i] + 1;
}
Optimizable :)
Fragile, though - needs to be cast back to float32 immediately
var f32 = new Float32Array(1000);
for (var i = 0; i < 1000; ++i) {
f32[i] = 2*f32[i] + 1;
}
Not optimizable, and also no parallel to overflow checks that ints can use :(
Math.fround: explicitly cast a number to 32-bit float precision
var f32 = new Float32Array(1000);
for (var i = 0; i < 1000; ++i) {
f32[i] = Math.fround(2*f32[i]) + 1;
}
Optimizable :)
Parallel to |0 which as mentioned before can help optimize integer math
fround support
In ES6, already in Firefox, Safari, Chrome (behind a flag), easy to polyfill:
Math.fround = Math.fround || (function() {
var temp = new Float32Array(1);
return function fround(x) {
temp[0] = +x;
return temp[0];
}
})();
or
Math.fround = Math.fround || function(x) { return x };
float32 microbenchmarks
| Matrix Inversions | Matrix Graphics | Exponential | FFT | |
| x86 | 33% | 60% | 30% | 16% |
| ARM | 38% | 38% | 24% | 33% |
% speedup with float optimizations (higher is better; source)
float32 - compiled benchmarks
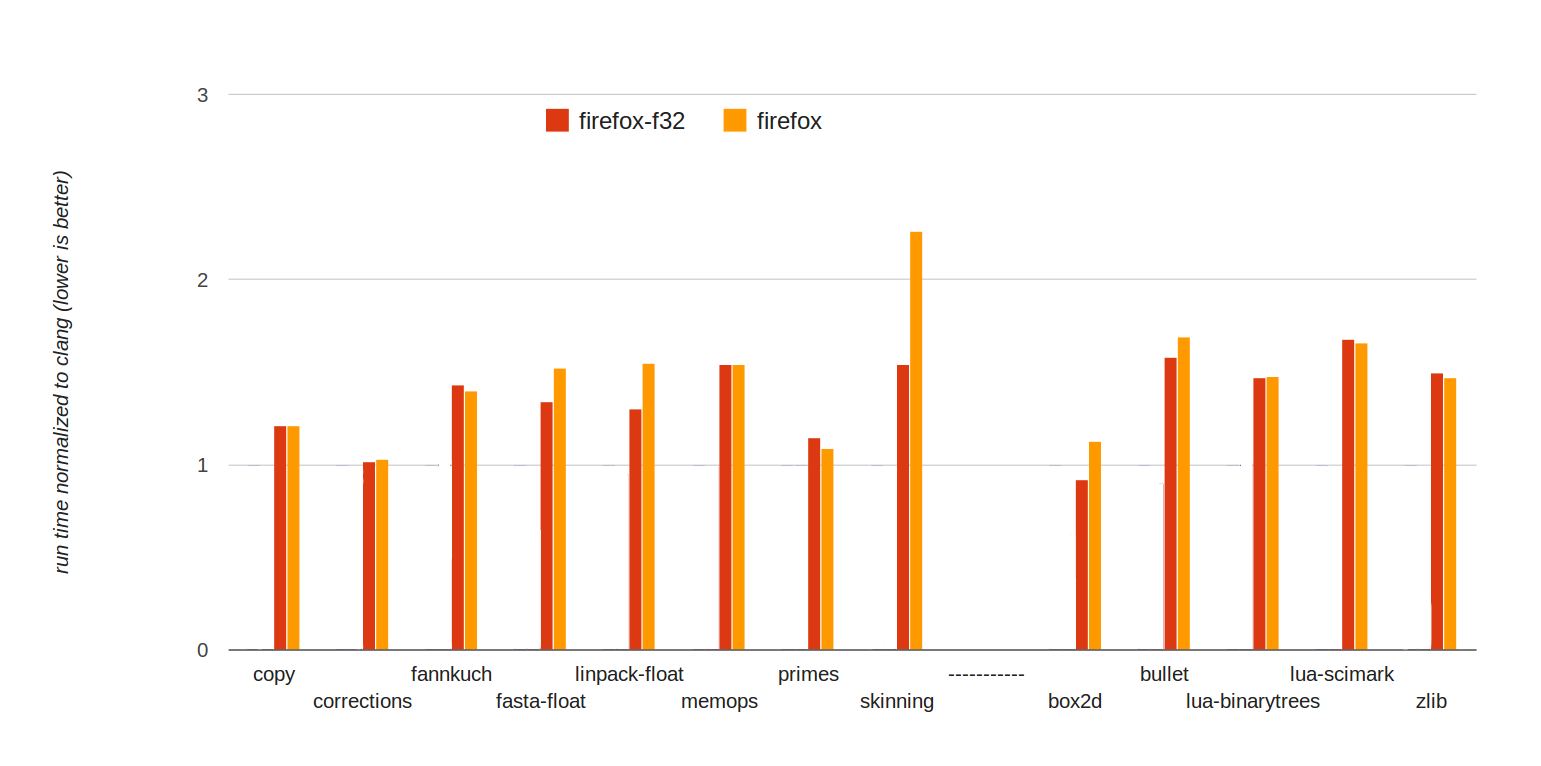
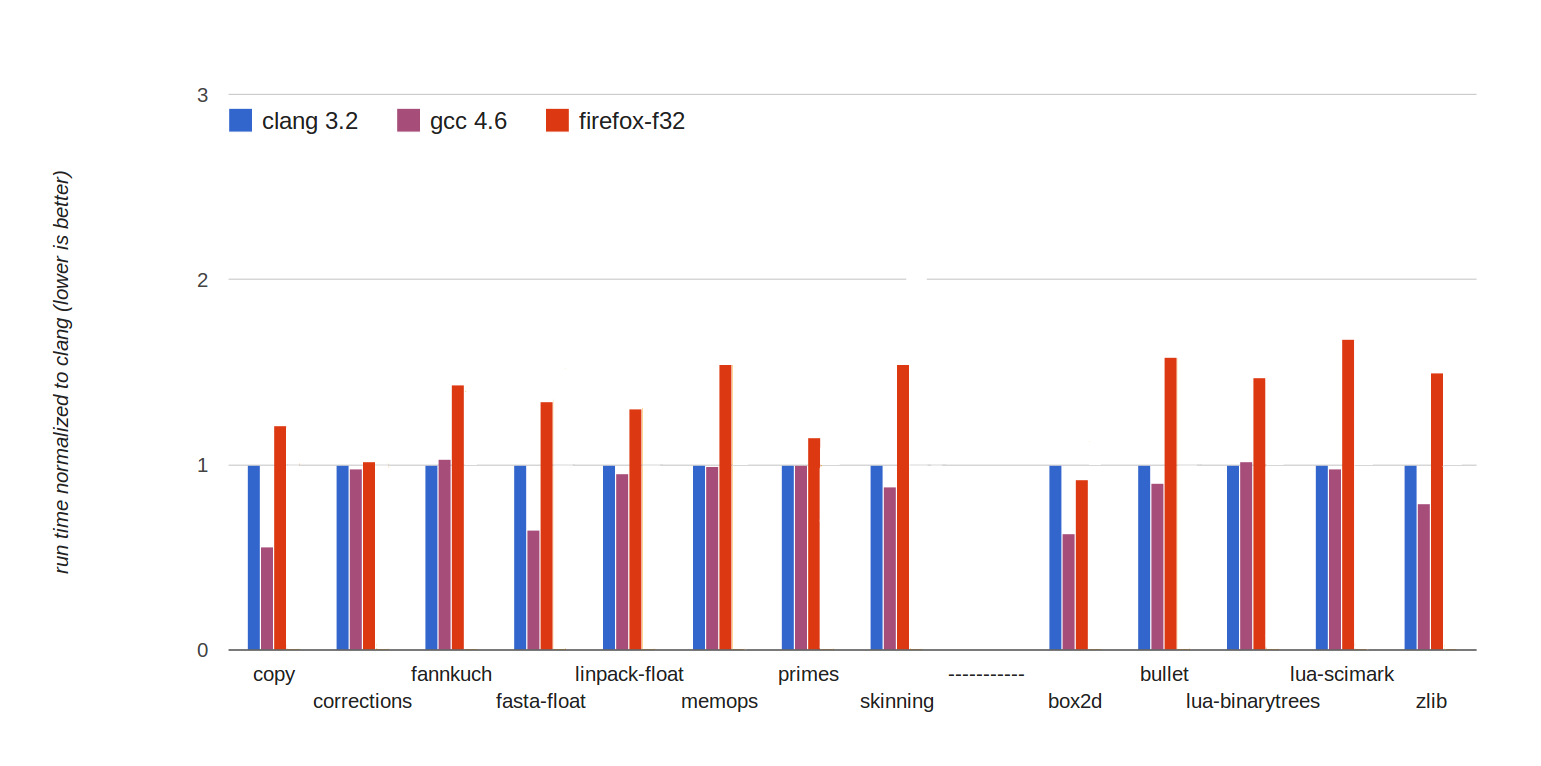
why is float32 faster?
Less precise, often less CPU cycles
Half the size, fewer cache misses
WebGL code often uses float32s, doing computation in float32 avoids conversions
Not yet, but possible: more registers/SIMD lanes
2. asm.js
Modern JS VMs have powerful optimizing JITs that operate on typed code
But many heuristics lie between source code and actually being fully typed and optimized
What if we made some JS code really really easy to optimize, with as few heuristics as possible?
asm.js is one way to do that
asm.js is a subset of JavaScript (not a new language, no new semantics, all 100% backwards compatible), written in a format that is extremely easy to optimize
E.g., the |0 pattern mentioned before:
function twice(x) {
x = x | 0;
return x + x | 0;
}
No need to profile types, can be optimized ahead of time (AOT) from source
asm.js example
function asmCode(global, env, buffer) {
'use asm';
var HEAP = new global.Uint8Array(buffer);
function fib_like(x) {
x = x|0;
if ((x >>> 0) < 2) return HEAP[x]|0;
return (fib_like(x-2|0)|0) + (fib_like(x-1|0)|0) | 0;
}
return fib_like;
}
asm.js workflow
Low-level and mostly inconvenient to write by hand - primarily intended as a compiler target
Emscripten is an open source LLVM-based compiler that generates asm.js from C/C++
Can compile existing C/C++ codebases, or write new ones - fits in with the "compile-to-js" movement (CoffeeScript, etc.)
asm.js Industry Adoption
Lots of interest from the games industry: Top-tier game engines starting to support HTML5 as a compilation target, using Emscripten to emit asm.js
Unity - Replacement for their popular web plugin
Unreal Engine - HTML5 as new target platform
& many others
Unity demo
Should see stuff like this ship on the web later this year, will be interesting times!
asm.js performance
Around 1.5x slower than native (67% of native speed)
As we saw, sufficient even for AAA game engines
asm.js Opts in Firefox
AOT - full optimizing JIT always run, using full type info
AOT done in parallel, results cached
No need for bailouts, we know many corner cases are impossible, etc.
On 64-bit, can do zero-cost bounds checks using a signal handler
Implementation notes
OdinMonkey is the optimization module for asm.js in SpiderMonkey
Fairly small amount of code
Mostly just type checks and sends the results into the normal optimizing JIT
3. Backtracking
Register
Allocator
We saw that JavaScript can get very close to native performance
When you get that close, every little thing starts to become significant, even register allocation
Backtracking Register Allocator
Inspired by LLVM's Greedy Register Allocator (added in LLVM 3.0)
LLVM results: 1-2% smaller code, up to 10% faster
Takes longer to run - and regalloc is already among the slowest phases - but worth it
How it works
Use priority queue of live ranges, instead of linear scan
If no free physical register, can backtrack - undo a previous allocation, if we need it more
Split live ranges to ensure physical registers for loops and other important places
SpiderMonkey followed LLVM's progress and in fact mirrored it
Like LLVM, began with a linear scan register allocator, improved it until it became too complex, then wrote a backtracking allocator
LLVM's experience and design has been very informative!
LLVM/SpiderMonkey Differences
Heuristics for when to split, whether to spill or split, etc.
SpiderMonkey values do not always require a physical register (e.g. for snapshots), can split live ranges based on that
Perf in SpiderMonkey
Most benchmark show little or no difference. But when there is a difference, it can be large!
21% speedup on octane-zlib on x86
7% speedup on x86-64, 11% speedup on ARM (more registers anyhow)
Other benchmarks: 29% speedup on emscripten-life on x86
Backtracking status
Enabled a few weeks ago on asm.js code, where it makes the most difference (closest to native speed) and we AOT
Heuristics need tuning before enabling everywhere, as compilation is slower, hopefully soon
Topics covered:
- float32
- asm.js
- backtracking register allocator